One of the things my daughter loves to do on Christmas Eve is look at the Santa tracker. Originally there was just the NORAD one, but now Google have one too. We won’t get into the fact that they can differ wildly in their assessment of where Father Christmas is at any given moment, but in our house Google has won out due to the proliferation of themed games that come with their tracker. One of these is a game where you have to draw a festive image and an AI has to guess what you’re drawing. I say ‘guess’ but that is an inaccurate description, it determines what you’re drawing (or fails to) based presumably on a large reference set of drawings of said objects passed through a diffusion model. Or perhaps it is a full diffusion model that is trying to reverse map to a specific set of prompts, it doesn’t really matter, the point is that it is probabilistically determining the most likely label for the image you are creating. Looking at the two images below, what struck me about them was the speed with which the programme identified one of them as a reindeer compared to the fact it ran out of time attempting to identify the other. This should give you a clear idea of which one the ‘AI’ managed to positively identify: the incomplete line drawing (2).
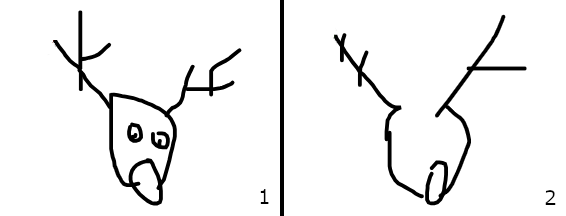
We can debate the various merits of my drawings from an art historical perspective, but what we cannot do is know why the algorithm identified one as a reindeer and not the other. Any human over the age of 5 would recognise both of those drawings as representations of reindeer given the context (ie drawing of a Christmas thing) but for some reason the ‘AI’ didn’t recognise my cartoon rudolf. We will never know the reason why and we can’t really find out. Even the engineers who built and trained the model wouldn’t be able to say categorically why it identified one and not the other. They may be able to do analysis of its training data and determine a possible gap in the data that would have helped with its identification of crap rudolf. It is possible that the game itself could be used to add to the training data, in that the images it failed to identify could be added in to the training data set so that the model would be more likely to recognise a similar image in future. However you wouldn’t want to risk this being unmoderated by a human, as someone could be drawing pictures of cars and if those automatically get categorised as reindeer in the training data your model’s going to break real quick. Even then you have the problem of overfitting. A probabilistic model (which all machine learning and AI models are) in its attempts to predict the most likely outcome always has the potential to be wrong. If it is 100% right on reindeer, it will be x% wrong on Santas that look a bit reindeer-y. The mechanics of model training are around finding the perfect midpoint between Santa looking reindeers and reindeer looking Santas. The side effect of this is that the odd crap rudolf will always go unrecognised.
This is why ‘hallucinations’ in generative AI will never be fixed, because they are a feature, not a bug. This fact is a critical consideration in how you apply AI tools to any aspect of your work or applications. For example if you want to have a Santa/Rudolf determiner, you might try an ‘agentic’ approach where you have one agent being the model that is trained to identify every possible Santa and another one that is trained to identify every possible Rudolf. The challenge here is that you still need a third ‘agent’ that is going to decide who’s right when the first two disagree, which really just kicks the can further down the road for 3x the compute. An easier (and more common) option for chat based solutions is to verify with the user (“it looks like you want to draw a crap Rudolf, is that correct?”), thus allowing them to validate the model’s output. I realise this is a common approach, as it de-risks edge cases, but I’ve got to say it’s pretty crappy UX. The whole point of AI is supposedly to remove friction from everyday processes, if it’s adding extra dumb questions into a process, where’s the benefit for users? If you’re automating a process that was previously purely manual, then adding in a few checks on the input isn’t a problem, in fact it’s quite sensible. If you’re replacing a web form with a chatbot that constantly asks dumb questions, have a word with yourself.
You might say no one uses images as an input for processes with deterministic outcomes, to which I’d reply “apart from a billion Chinese people texting.” But image recognition for typing Chinese characters is a well used, massively tested, well refined, well trained set of machine learning algorithms with a distinct and finite set out possible outcomes alongside easy, reflexive user validation. It is a problem solved by ‘AI’ so long ago that it is barely even considered AI any more. In contrast there are probably only a small number of serious business uses for new AI tools that work on image recognition – I’m not sure my Santa/Rudolf sorter is going to get seed funding, – but these issues would be encountered with text recognition too. Perhaps to a lesser degree because there is less complexity in modelling text*, but only if you’re thinking about modelling speech rather than modelling communication. Whilst humans use the same set of linguistic tools to communicate, those words and sentences won’t hold exactly the same meaning for everyone. Obviously, everyone’s understanding of most nouns is similar enough that we can functionally understand what each other means. If I say “chicken” to you, the image of a chicken in your head won’t be the same as the one in my head, but we both understand what a chicken is and that we’re both comprehending a bird that lays eggs and makes a clucking noise. However, as soon as we get into more complex concepts or even less familiar words, that understanding becomes less dependably equivalent. When discussing complex aspects of a solution with colleagues we will often have to define that concept in multiple ways, quite often to find that we are talking about the same (or nearly the same) thing that is visualised in our minds differently or even just that we use different linguistic concepts to describe. You might think that it would be better if we just all used the same words to describe everything, but I would hard disagree. Those conversations open up different viewpoints on a potential solution, uncovering ideas that may be essential in successful delivery, but they also expand and reinforce our contextual word knowledge.
Perhaps because she spends too much time around me, my daughter has a penchant for big words. Like most other kids her age she will regularly give rise to wonderfully entertaining malapropisms through her experiments with these words. I try to find ways to explain the correct meanings and usages without discouraging her from trying them out, because she won’t learn if she isn’t told but more importantly she won’t learn if she doesn’t try. I’m sure this is common for children, but when they learn to read, the cycle of correction can get broken. For many years I thought ‘messianic’ meant really like messy all over the place, like a person who is constantly drunk and clumsy. That is obviously not what it means, but I was well into my 20s before I discovered that. I can’t say that it was a word I used regularly, but one time when I did, my wife questioned my use of it in the context and I realised how wrong I’d been. Again I don’t think it’s uncommon for people to retain these kinds of malapropistic conceptions of words or phrases well into adulthood and possibly all their life. However, they are of little real world consequence, because when a person uses one of these words or phrases incorrectly in conversation, the other person is usually able to determine the correct inferred meaning from the context of the conversation. This is because humans use words to interpret meaning, whereas an LLM has no concept of the meaning of words. For an LLM words are data points within known sentence structures each with probabilistic relationships to each other in terms of likely inputs and outcomes. This is why if I tell a child the correct meaning and usage of a word, they will subsequently use the correct meaning but if I tell an LLM the correct meaning, it may start to use the correct meaning, but it will also retain the old meanings (unless I remove all reference to them and retrain it). There is therefore still a non-zero chance that it will use the word incorrectly sometimes.
One would hope that an LLM has been created with the correct linguistic structures for reference, or at least that the sheer volume of training data would shake out to the correct linguistic structures, but even if that is the case, one still has to account for the lack of understanding of contextual meaning. My particular industry is one that many people engage with but most people don’t really understand, so the chance that someone will ring up and convey the incorrect meaning using some of the correct words is probably quite high. A human agent might be able to determine the meaning of what the caller is saying despite the misuse of key words or phrases, an LLM based ‘agent’ doesn’t have a concept of meaning, so it can only determine the most probable outcome from the text presented to it based on reference to all the training text it has consumed. There is very little casual writing about pensions. There is very little fiction, drama or poetry about pensions. The available training data for pensions is the dry language of technical documentation, ‘how to’ guides and legislation. Probabilistic evaluations using this training set are only going to arrive at the correct conclusion if the input language is as correct as the training data set. Obviously a full LLM will be able to infer a greater range of ‘meaning’ than would a model trained solely on the industry corpus, but that actually adds a greater degree of uncertainty. If I google ‘GMP’ I’ll get as many results for Greater Manchester Police as I do for Guaranteed Minimum Pension. The industry specific corpus should account for this in that the latter would be given more weight in my hypothetical ‘pensions agent’ model, but the obvious words or phrases don’t carry the most risk of misinterpretation.
There is a joke about training a robot barman where it is taught every drink the bar serves, then every drink known, then all the things that sound like drinks but are not drinks, etc and then as soon as the bar opens a customer comes in and asks where the toilet is. I think it’s supposed to show that there will always be an edge case that your users find before you do. The challenge around implementing something where all of language (available online) is a possible input and a possible reference, is knowing what potential outcomes to test for. Defining all the available ‘cocktail recipes’ (ie defining your expected outcomes) is obviously a good start, especially if the result of any interaction can only be one of these outcomes or referral to a human. However this still doesn’t guarantee that the user will be routed to the correct outcome every time. Ultimately nothing will, so it is important to include as many opportunities for the user to validate actions as possible without significantly degrading the overall user experience. Ultimately you need to make sure that you’re comfortable with the risk, however small, of a user taking an action that is not the one they intended to take. Granted anything significant is going to hand a user off to a deterministic process with multiple checks in it, but that doesn’t always stop people, especially if a person (or something that speaks like one) has told them they are doing the right thing.
At the end of the day, my Rudolf/Santa picker is going nowhere and not just because it has no practical value (when did that stop anyone?), but because of the other considerations we all need take into account. We can build safeguards and checks in to cover the unknown unknowns, but if there is risk that an unknown unknown-unknown could have material consequences, we need to think again whether deployment of a probabilistic model is the right choice in that specific circumstance.
*although not apparently in generating text. Presumably this is because text requires the model to use the same amount of compute to predict each word, whereas images are a single whole object generated in one go.
Leave a Reply